The digit classifier from the notes keeps confusing 4 and 9.
What could you change to improve the classifier?
Think alone 1 min, then discuss with your neighbour 2 min.
03:00
How a network learns
Neurons
A neuron receives inputs,weights them,sums upand (maybe) activates.
Weighted sum: \(z = \sum_i w_i x_i + b\)
Activation functions determine the output:
Binary Step: Fires (\(1\)) or stays silent (\(0\)) based on a strict threshold.
Sigmoid / Tanh: Squashes \(z\) into a smooth probability range (like 0 to 1), e.g., \(\sigma(z) = \frac{1}{1 + e^{-z}}\).
ReLU: Passes positive values through, outputs \(0\) for any negative \(z\).
Recap: weights and bias
Figure 1: Weights in a neural network
Positive weight: input encourages the neuron to fire
Negative weight: input discourages firing
Bias: shifts the firing threshold
Weights and the bias are the knobs learning adjusts
Recap: the digit network
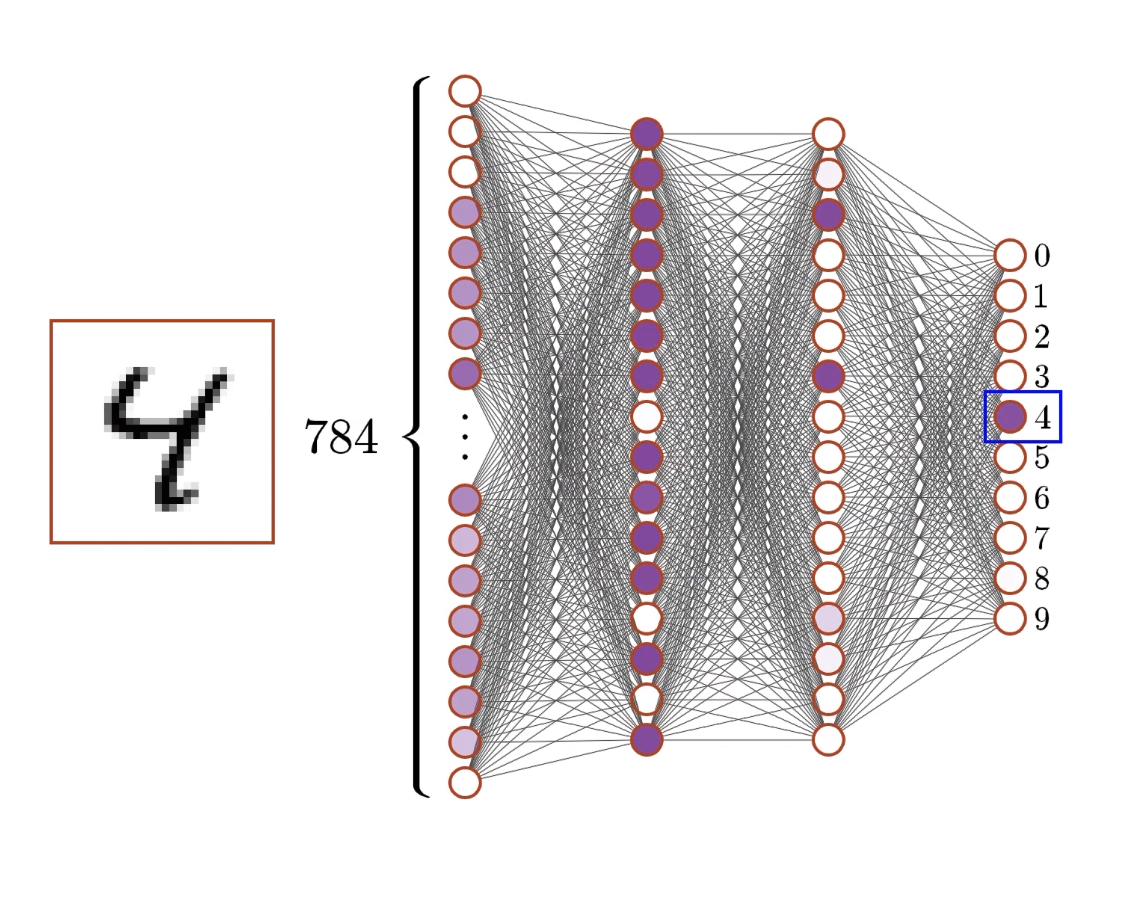
From 28×28 pixels
to a neural network
to 10 probabilities
Input: 784 neurons (one per pixel)
Hidden: 2 × 16 neurons
Output: 10 neurons (digits 0 to 9)
Total: about 13,000 adjustable parameters
Figure 2: Network architecture for digit recognition
Recap: the learning loop
Forward pass: make a prediction
Cost: measure how wrong it is, \(C = \sum_j (a_j - y_j)^2\)1
Backpropagation: find which weights are responsible
Gradient descent: nudge each weight to reduce the cost
Repeat with the next example
Exercise A: be the network
A single neuron has two inputs with weights \(w_1 = 0.5\), \(w_2 = -0.4\), bias \(b = 0.1\). You feed it one example: \(x_1 = 1.0\), \(x_2 = 0.0\). The correct answer is \(y = 1\).
For each of \(w_1\), \(w_2\), \(b\), decide whether to increase,decrease, or leave unchanged to reduce the cost. Justify each in one sentence.
Why is \(w_2\) a special case here?
15:00
Transformers & LLMs
Recap: the transformer pipeline
Digits have fixed size; language has variable length and order matters. The transformer is built for sequences.
Running example: “Was the bank flooded?”
Tokenize: split the text into tokens, the units the model processes
Embed: give each token a vector, a fixed starting point that is not yet context-aware
Transform (×N): every block runs attention, then a feed-forward network
Unembed: turn the last token’s final vector into a probability over the vocabulary
Recap: embeddings
Embeddings are a starting point, not a meaning.
Each token maps to a high-dimensional vector (a lookup); similar tokens get similar vectors
Directions in this space encode meaning: “king” − “man” + “woman” ≈ “queen”
“Bank” maps to the same vector in every sentence, financial or river. That is the problem attention solves next.
Recap: attention in three steps
Each token produces three vectors via learned matrices:
Query\(W_Q\): what context do I need?
Key\(W_K\): what context can I offer?
Value\(W_V\): what information do I send?
For every token, in parallel:
Scores:Query · Key for each pair, how relevant is each token to me?
Softmax: turn the scores into weights between 0 and 1 that sum to 1
Weighted sum: mix the Value vectors using those weights
Attention does not pick one token; it weights all of them.
For “bank”: \(0.6 \times V(\text{flooded}) + 0.3 \times V(\text{was}) + 0.1 \times V(\text{the}) + \dots\) → the riverbank meaning.
Recap: unembedding and temperature
The last token’s final vector carries the whole context, since through attention it has seen every earlier token.
Last vector × \(W_U\) → a raw score for every token
Softmax turns scores into probabilities
Temperature\(T\) reshapes the distribution before sampling
“The trophy did not fit in the suitcase because it was too big.”
Which word should “it” attend to most strongly: trophy or suitcase? Why?
Now change big to small. What does “it” attend to now?
Exercise C: temperature
After “The trophy was too”, the model outputs raw scores: big: 2.0, large: 1.0, heavy: 0.5.
Compute the probabilities for T = 0.5 and T = 2.0.
The ranking is the same at both temperatures (big > large > heavy). So how can temperature lead to different outputs?
Which T suits factual output?
Exercise D: quick check
True ore false?
A transformer never sees raw text; it works on tokens turned into vectors.
Before attention, a word’s embedding is the same regardless of surrounding context.
Attention picks the single most relevant word and ignores all the others.
The attention plus feed-forward block is applied only once.
A higher sampling temperature makes the output more random.
15:00
Wrap-up
Key takeaways
How a network learns
A neuron is a weighted sum plus an activation; weights and bias are the only things that change
Learning is a loop: predict, measure cost, find responsible weights, nudge them down the gradient
“Training” is this one small step repeated over millions of examples and thousands of parameters
Transformers & LLMs
Embeddings put meaning into geometry; attention reshapes each word’s vector using its context
Query-key scores decide relevance; values carry the information that gets mixed in
The final vector becomes next-token probabilities; temperature tunes reliability vs creativity
Bridge
Same machinery, different scale: the digit neuron and GPT both learn by nudging weights down a gradient.
What breaks, or has to change, when you go from 13,000 parameters to billions?
Q&A
Literature
Footnotes
This is the Quadratic Cost (or Mean Squared Error) formula. It calculates the squared difference between the network’s actual output (\(a_j\)) and the correct target label (\(y_j\)) across all final output neurons (\(j\)). Squaring the error ensures the result is always positive and penalizes larger mistakes more heavily.